| You Are What You Decide: A Journey in Automation of Our Selves. |
How To Learn The True Intent of Society?
One of the major goals of the Infinity Project, is to help ourselves to define and pursue common goal: "if we are able to define our common goal, the problem of creating friendly artificial intelligence reduces to creating an optimization system to optimize for our common goal."
We started with a realization of categories (need, goal, idea, plan, step, task, work), which people seem to use when they break down all of the work they do, and built a goal-pursuit/task-management system to help people define their goals explicitly.
Unfortunately, people don't always know what they want, and are often unable to explicitly define their true goals. Fortunately, people almost always try to do something in order to move towards the achievement of their goals. They speak through their actions. Today it is capitalism and free market that approximates peoples goals, however, ideally, intelligent systems would adapt to what people do, by inferring people's goals at large, and assisting in their achievement.
But how do we make sure that the inferred goals are true goals for our optimization system to optimize for?
Well, that is what one of the Stanford researcher Long Ouyang, an FLI nominee, is focusing on. The problem of determining goals from sequences of actions seem to be in principle equivalent to parsing sentences from sequences of letters:
In case of parsing sentences, we are identifying non-terminal symbols $N$ like:
- S - Sentence
- NP - Noun Phrase
- VP - Verb Phrase
- PP - Preposition Phrase
- N - Noun
- V - Verb
- P - Preposition,
In parsing people's needs, we may be identifying non-terminal symbols $N$ like:
- N - Need
- G - Goal
- I - Idea
- P - Plan
- S - Step
- T - Task
- W - Work,
So, it appears that without the loss of generality, we can consider that letters correspond to actions, and that by learning to infer what kind of word a user meant by a sequence of letters, we learn to infer what work a user meant through a sequence of actions. In other words, if the research is successful, we can transfer it directly to the learning society's needs from its actions.
The problem of Understanding True Intent
We could say that a computer understands true intent, or meaning, if it parses the sentence correctly. Just like with sentence ambiguity as shown in the example below, there may exist similar ambiguity in understanding needs from sequences of actions.
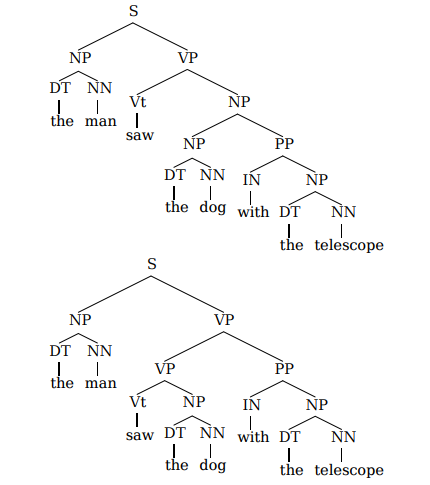
Whether a computer parses a sentence correctly depends subtly on the probabilities associated with the production rules used to parse the sentence (or need), and if we know the probability distributions, according to which it has to correctly parse the sentences, it is possible to generate grammatically correct sentences (or sequences of actions that makes sense in satisfying needs, according to society's preferences). What could possibly go wrong?
On one hand, we may fail to identify the higher level non-terminal symbol, completely misunderstanding the actual intent of an action (e.g., showing how to play ping-pong, and AI system understanding that the intent is to minimize an opponent's chances of hitting the ball back, whereas true intent may be to support one's health). On the other hand, probability distributions that define production rules, could be non-linearly dependent we may fail to understand what decomposition is appropriate under what circumstances (e.g., it may be appropriate to get meat from a refrigerator to cook soup, but not from a living domestic pet). Both kind of situations well illustrated in the 2008 year move "Cyborg She" ([video] (21 sec), [video] (53 sec).) (show note)
Bayesian rule to model intended sequences
We don't know a full alphabet of all possible atomic actions (e.g., a human may have actions like stand up, look around, walk forward,... and so on, but the full list of possible atomic actions may be quite long) , so, without loss of generality, suppose that a sequence of actions is represented by a sequence of letters, and we want to infer a rule (could be a full-blown grammar), which produced them.
For the sake of simplicity, suppose that our grammar is something simpler, like the one below, suited for capturing simple regular expressions, and our task is to infer a regular expression that captures the intended sequence generation rule (the regex) from the user's input characters. I'm referring to the information provided by Long Ouyang [1] below:
In parsing people's needs, we may be identifying non-terminal symbols $N$ like:
- REGEX
- BRANCH
- PPART
- CHAR
Suppose the user had entered a few letters $x_1$ and $x_2$, and we must return candidate regexes $r_1$, $r_2,...$ ranked in some order. This maps nicely onto the problem of computing posterior probability distribution $P(r | {x_1, x_2})$, which captures the probability of a regex $r$ given the observed evidence $x$. Bayes' Rule allows us to decompose the posterior probability into two terms: the prior probability of a regex and the likelihood of the data given that regex.
How can we use this to differentiate between true intent, and not true intent?
Literal vs Pragmatic program synthesizers
An intelligent system could be said to have understood the true intent, if after given some examples of input sequences, it generates intended sequences of symbols. It can either interpret the input literally ("find a rule that generates shown behavior"), or pragmatically ("infer user's goal from the shown behavior, and choose the optimal production rules to help achieve that goal, not necessarily repeating the same behavior shown by user") (show note).
It is convenient to use the Bayes decomposition to make such a distinction by assuming that both the literal and pragmatic program synthesizers share the same prior distributions, but differ in the way that they deal with estimating the Bayesian likelihood above, namely, having same prior probability but differ in the way they estimate likelihood.
Let's take a look at the examples from [1].
Literal
In both cases, let's assume that our prior probability is given by a PCFG (probabilistic context-free grammar). A probabilistic, meaning, that we know the discrete probability distributions of rewrites associated with each production rule uniquely associated with each non-terminal symbol.
REGEX -> BRANCH [0.99] | SUB-REGEX [1.0] BRANCH -> PART [0.3] | SUB-BRANCH [0.7] PART -> CHAR [0.9] | CHAR + [0.05] | CHAR * [0.05] CHAR -> 'a' [0.33..] | 'b' [0.33..] | 'c' [0.33..]
This can be coded with a probabilistic programming language (WebPPL) as follows:
///fold: var geometric = function(p) { return flip(p)?1+geometric(p):1 } /// var sample_regex = function() { var n = geometric(0.99) var branches = sample_branch().repeat(n) return branches } var sample_branch = function() { var n = geometric(0.3) var parts = sample_part().repeat(n) return parts } var sample_part = function() { var char = uniformDraw(["a","b","c"]) if(flip(1.0)) { return char+uniformDraw(["+","*"]) } else { return char } } sample_regex()
Pragmatic
[...unfinished...]
[1] -- Detailed version of http://futureoflife.org/data/full-proposal-files/abstract_3.pdf.Support! (readme)





